In this article I would like to take a look at the data we have in the dutch primary school dataset. I want to investigate what variables I have, do I have some outliers or not and also is there any relationship between features.
General info about dataset and its variables
Read the data from a .cvs file
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
data = pd.read_csv("./make_school_data/main/output/Score.csv", error_bad_lines=False, sep=',', encoding = "ISO-8859-1")
General information exploration
print(data.shape)
print(data.columns)
data.head()
(31300, 33)
Index(['SCHOOL_ID', 'DATUM', 'INSTELLINGSNAAM_VESTIGING', 'POSTCODE_VESTIGING',
'PLAATSNAAM', 'GEMEENTENAAM', 'PROVINCIE', 'SOORT_PO',
'DENOMINATIE_VESTIGING', 'EXAMEN', 'EXAMEN_AANTAL', 'EXAMEN_GEM',
'REKENEN_LAGER1F', 'REKENEN_1F', 'REKENEN_1S', 'REKENEN_2F',
'LV_LAGER1F', 'LV_1F', 'LV_2F', 'TV_LAGER1F', 'TV_1F', 'TV_2F', 'VSO',
'PRO', 'VMBO', 'VMBO_HAVO', 'HAVO', 'HAVO_VWO', 'VWO',
'ADVIES_NIET_MOGELIJK', 'TOTAAL_ADVIES', 'LJ8', 'ZIT'],
dtype='object')
| SCHOOL_ID | DATUM | INSTELLINGSNAAM_VESTIGING | POSTCODE_VESTIGING | PLAATSNAAM | GEMEENTENAAM | PROVINCIE | SOORT_PO | DENOMINATIE_VESTIGING | EXAMEN | ... | PRO | VMBO | VMBO_HAVO | HAVO | HAVO_VWO | VWO | ADVIES_NIET_MOGELIJK | TOTAAL_ADVIES | LJ8 | ZIT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 000AP_2015 | 2015 | De Schanskorf | 2715BT | ZOETERMEER | Zoetermeer | Zuid-Holland | Bo | Gereformeerd vrijgemaakt | CET | ... | 0 | 1 | 0 | 5 | 1 | 1 | 0 | 11 | 13 | 0 |
| 1 | 000AR_2015 | 2015 | BS "De Maasparel" | 6109AM | OHE EN LAAK | Maasgouw | Limburg | Bo | Rooms-Katholiek | CET | ... | 0 | 1 | 0 | 7 | 0 | 6 | 0 | 18 | 17 | 0 |
| 2 | 000AZ_2015 | 2015 | De Kiezel en de Kei | 2971AR | BLESKENSGRAAF CA | Molenwaard | Zuid-Holland | Bo | Openbaar | CET | ... | 1 | 3 | 5 | 3 | 2 | 4 | 0 | 22 | 19 | 3 |
| 3 | 000BA_2015 | 2015 | OBS De Klimboom | 6666EB | HETEREN | Overbetuwe | Gelderland | Bo | Openbaar | CET | ... | 1 | 1 | 0 | 1 | 4 | 0 | 0 | 12 | 24 | 5 |
| 4 | 000BB_2015 | 2015 | Obs Letterwies | 9944AR | NIEUWOLDA | Oldambt | Groningen | Bo | Openbaar | CET | ... | 0 | 7 | 0 | 5 | 0 | 2 | 0 | 16 | 15 | 2 |
5 rows × 33 columns
print(data.nunique(axis=0))
data.describe().apply(lambda s: s.apply(lambda x: format(x, 'f')))
SCHOOL_ID 31300
DATUM 5
INSTELLINGSNAAM_VESTIGING 6287
POSTCODE_VESTIGING 6499
PLAATSNAAM 1844
GEMEENTENAAM 413
PROVINCIE 12
SOORT_PO 2
DENOMINATIE_VESTIGING 17
EXAMEN 7
EXAMEN_AANTAL 132
EXAMEN_GEM 14244
REKENEN_LAGER1F 31
REKENEN_1F 68
REKENEN_1S 88
REKENEN_2F 59
LV_LAGER1F 18
LV_1F 50
LV_2F 113
TV_LAGER1F 31
TV_1F 66
TV_2F 98
VSO 16
PRO 32
VMBO 48
VMBO_HAVO 26
HAVO 45
HAVO_VWO 31
VWO 63
ADVIES_NIET_MOGELIJK 35
TOTAAL_ADVIES 144
LJ8 134
ZIT 29
dtype: int64
| DATUM | EXAMEN_AANTAL | EXAMEN_GEM | REKENEN_LAGER1F | REKENEN_1F | REKENEN_1S | REKENEN_2F | LV_LAGER1F | LV_1F | LV_2F | ... | PRO | VMBO | VMBO_HAVO | HAVO | HAVO_VWO | VWO | ADVIES_NIET_MOGELIJK | TOTAAL_ADVIES | LJ8 | ZIT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | ... | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 | 31300.000000 |
| mean | 2017.018818 | 27.589904 | 399.593409 | 1.896741 | 9.936709 | 8.896326 | 1.374026 | 0.465304 | 5.412875 | 16.225623 | ... | 0.395719 | 5.645911 | 2.177348 | 5.458562 | 2.478594 | 5.804217 | 0.142077 | 28.463482 | 21.855974 | 2.482300 |
| std | 1.400569 | 17.059502 | 196.257453 | 2.675862 | 8.878866 | 10.018202 | 4.616997 | 1.167952 | 5.478845 | 14.902800 | ... | 1.516142 | 4.714144 | 2.688906 | 4.739689 | 3.272615 | 6.061055 | 1.420359 | 17.463933 | 19.278557 | 2.909880 |
| min | 2015.000000 | 5.000000 | 50.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 2016.000000 | 15.000000 | 197.370536 | 0.000000 | 3.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 5.000000 | ... | 0.000000 | 2.000000 | 0.000000 | 2.000000 | 0.000000 | 2.000000 | 0.000000 | 16.000000 | 6.000000 | 0.000000 |
| 50% | 2017.000000 | 24.000000 | 532.818182 | 1.000000 | 9.000000 | 6.000000 | 0.000000 | 0.000000 | 4.000000 | 14.000000 | ... | 0.000000 | 5.000000 | 1.000000 | 4.000000 | 1.000000 | 4.000000 | 0.000000 | 25.000000 | 20.000000 | 2.000000 |
| 75% | 2018.000000 | 35.000000 | 536.545455 | 3.000000 | 15.000000 | 13.000000 | 0.000000 | 0.000000 | 8.000000 | 24.000000 | ... | 0.000000 | 8.000000 | 3.000000 | 8.000000 | 4.000000 | 8.000000 | 0.000000 | 37.000000 | 31.000000 | 4.000000 |
| max | 2019.000000 | 163.000000 | 758.533333 | 35.000000 | 82.000000 | 106.000000 | 63.000000 | 20.000000 | 54.000000 | 125.000000 | ... | 36.000000 | 51.000000 | 28.000000 | 67.000000 | 35.000000 | 109.000000 | 102.000000 | 227.000000 | 161.000000 | 53.000000 |
8 rows × 24 columns
We have 31300 observations and 33 variables. From the last table with descriptive statistics we can see that some of the columns (like EXAMEN_AANTAL, REKENEN_LAGER1F, REKENEN_1F, REKENEN_1S, etc.) has max value much bigger than its mean, standart deviation or min value. It could mean that this variables have outliers or they don’t follow normal distribution. Let’s analyse them first.
Continuous variables exploration
numeric_data = data.select_dtypes(include=[np.number])
print(numeric_data.columns)
numeric_data.head()
Index(['DATUM', 'EXAMEN_AANTAL', 'EXAMEN_GEM', 'REKENEN_LAGER1F', 'REKENEN_1F',
'REKENEN_1S', 'REKENEN_2F', 'LV_LAGER1F', 'LV_1F', 'LV_2F',
'TV_LAGER1F', 'TV_1F', 'TV_2F', 'VSO', 'PRO', 'VMBO', 'VMBO_HAVO',
'HAVO', 'HAVO_VWO', 'VWO', 'ADVIES_NIET_MOGELIJK', 'TOTAAL_ADVIES',
'LJ8', 'ZIT'],
dtype='object')
| DATUM | EXAMEN_AANTAL | EXAMEN_GEM | REKENEN_LAGER1F | REKENEN_1F | REKENEN_1S | REKENEN_2F | LV_LAGER1F | LV_1F | LV_2F | ... | PRO | VMBO | VMBO_HAVO | HAVO | HAVO_VWO | VWO | ADVIES_NIET_MOGELIJK | TOTAAL_ADVIES | LJ8 | ZIT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2015 | 11 | 534.3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 1 | 0 | 5 | 1 | 1 | 0 | 11 | 13 | 0 |
| 1 | 2015 | 18 | 539.8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 1 | 0 | 7 | 0 | 6 | 0 | 18 | 17 | 0 |
| 2 | 2015 | 22 | 532.9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 3 | 5 | 3 | 2 | 4 | 0 | 22 | 19 | 3 |
| 3 | 2015 | 11 | 536.2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 1 | 0 | 1 | 4 | 0 | 0 | 12 | 24 | 5 |
| 4 | 2015 | 16 | 531.3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 7 | 0 | 5 | 0 | 2 | 0 | 16 | 15 | 2 |
5 rows × 24 columns
We can see that DATUM is actually a categorical variable, so we need to remove it from numeric_data. But everything else is continuous, so let’s take a look at its distribution:
numeric_data.drop('DATUM', 1, inplace = True)
print(numeric_data.columns)
Index(['EXAMEN_AANTAL', 'EXAMEN_GEM', 'REKENEN_LAGER1F', 'REKENEN_1F',
'REKENEN_1S', 'REKENEN_2F', 'LV_LAGER1F', 'LV_1F', 'LV_2F',
'TV_LAGER1F', 'TV_1F', 'TV_2F', 'VSO', 'PRO', 'VMBO', 'VMBO_HAVO',
'HAVO', 'HAVO_VWO', 'VWO', 'ADVIES_NIET_MOGELIJK', 'TOTAAL_ADVIES',
'LJ8', 'ZIT'],
dtype='object')
for feature in numeric_data:
new_data=numeric_data.copy()
new_data[feature].hist(bins=25)
plt.xlabel(feature)
plt.ylabel("Count")
plt.title(feature)
plt.show()
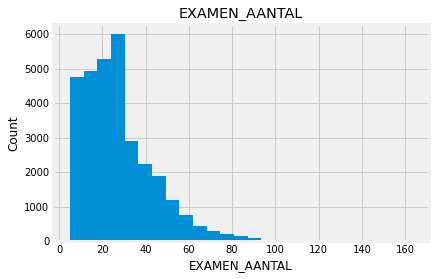
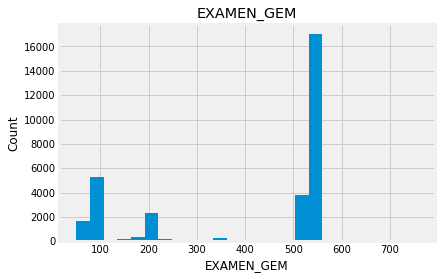
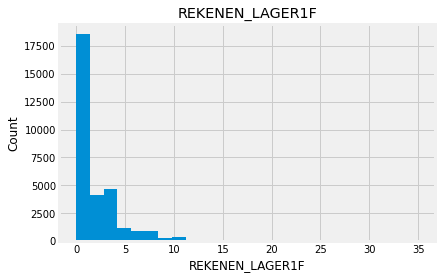
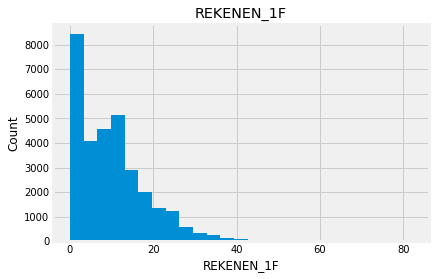
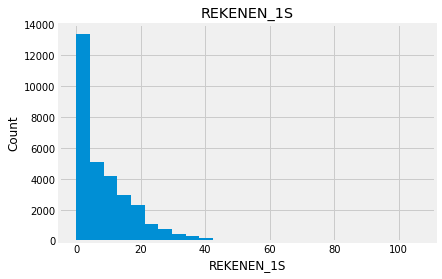
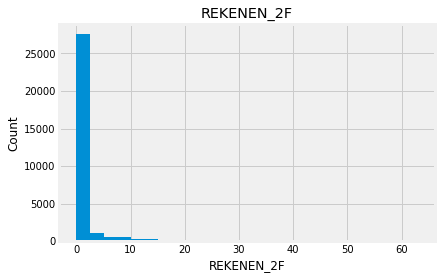
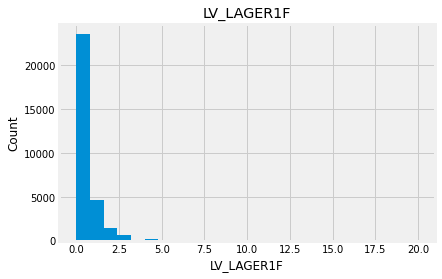
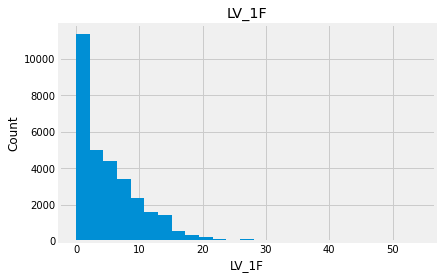
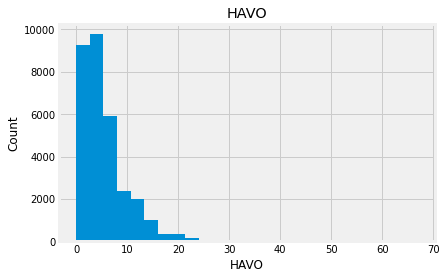
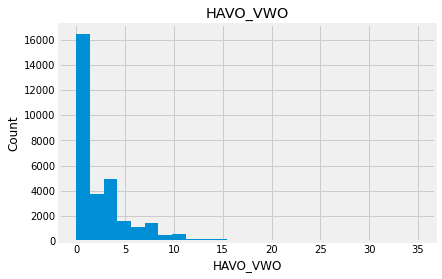
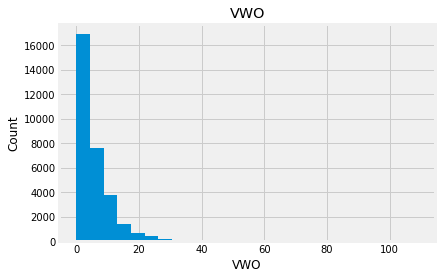
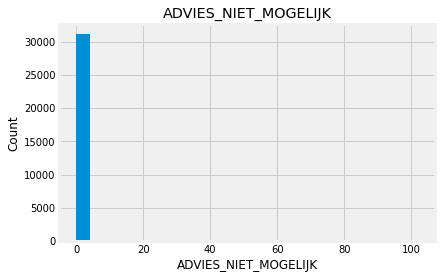
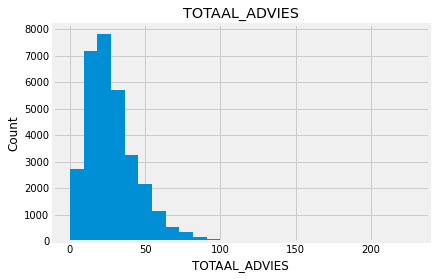
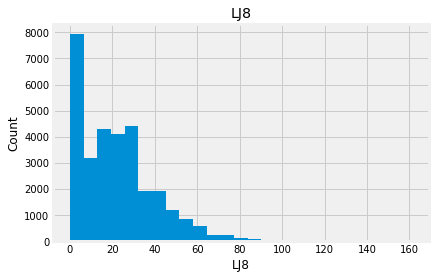
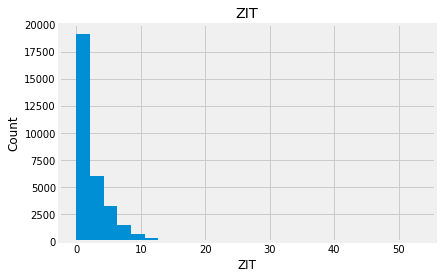
Indead we can see that almost none of the variables looks like a normally distributed variable. I think it can be so because this dataset is a mix of data for different final exams and different school educational systems. If we would select some specific data (e.g. an exam score for only one type of exam for a specific year) we get a more normalized data. Let’s go to categorical variables and see what we have there.
Categorical variables
categorical_data = data.drop(numeric_data, axis=1)
categorical_data = categorical_data.drop('SCHOOL_ID', 1)
print(categorical_data.shape)
categorical_data.head()
(31300, 9)
| DATUM | INSTELLINGSNAAM_VESTIGING | POSTCODE_VESTIGING | PLAATSNAAM | GEMEENTENAAM | PROVINCIE | SOORT_PO | DENOMINATIE_VESTIGING | EXAMEN | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2015 | De Schanskorf | 2715BT | ZOETERMEER | Zoetermeer | Zuid-Holland | Bo | Gereformeerd vrijgemaakt | CET |
| 1 | 2015 | BS "De Maasparel" | 6109AM | OHE EN LAAK | Maasgouw | Limburg | Bo | Rooms-Katholiek | CET |
| 2 | 2015 | De Kiezel en de Kei | 2971AR | BLESKENSGRAAF CA | Molenwaard | Zuid-Holland | Bo | Openbaar | CET |
| 3 | 2015 | OBS De Klimboom | 6666EB | HETEREN | Overbetuwe | Gelderland | Bo | Openbaar | CET |
| 4 | 2015 | Obs Letterwies | 9944AR | NIEUWOLDA | Oldambt | Groningen | Bo | Openbaar | CET |
plt.figure(figsize=(5, 5))
ax = sns.countplot(y='DATUM',data=categorical_data, order = data['DATUM'].value_counts().index)
ax.set_title('Amount of schools per year')
Text(0.5, 1.0, 'Amount of schools per year')
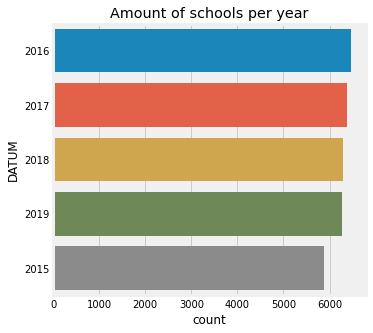
Let’s take a look at the plots of the variables with relatively small amount of unique values. I will show a plot for variables like EXAMEN or GEMEENTENAAM. I won’t show plots for variables like INSTELLINGSNAAM_VESTIGING because we already know it has 6287 of unique values.
plt.figure(figsize=(8, 8))
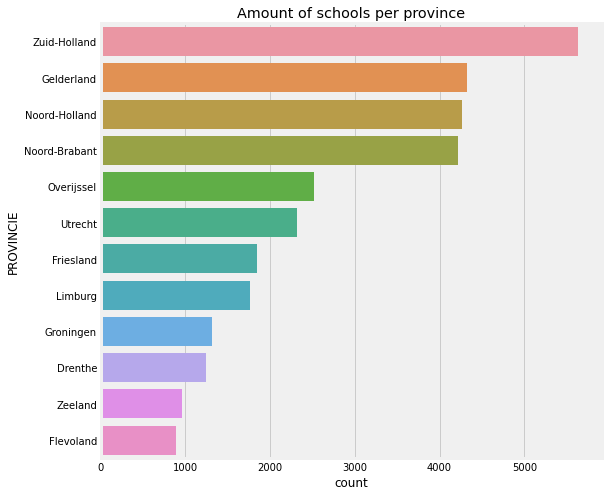
ax = sns.countplot(y='PROVINCIE',data=categorical_data, order = data['PROVINCIE'].value_counts().index)
ax.set_title('Amount of schools per province')
Text(0.5, 1.0, 'Amount of schools per province')
plt.figure(figsize=(8,8))
ax = sns.countplot(x='GEMEENTENAAM',data=categorical_data, order = data['GEMEENTENAAM'].value_counts().index)
ax.set_title('Amount of schools per GEMEENTE')
Text(0.5, 1.0, 'Amount of schools per GEMEENTE')
plt.figure(figsize=(3, 3))
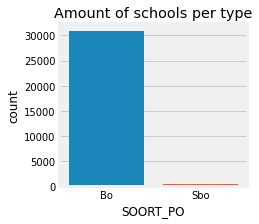
ax = sns.countplot(x='SOORT_PO', data=categorical_data, order = data['SOORT_PO'].value_counts().index)
ax.set_title('Amount of schools per type')
Text(0.5, 1.0, 'Amount of schools per type')
plt.figure(figsize=(8, 8))
ax = sns.countplot(y='DENOMINATIE_VESTIGING',data=categorical_data, order = data['DENOMINATIE_VESTIGING'].value_counts().index)
ax.set_title('Amount of schools per denomination')
Text(0.5, 1.0, 'Amount of schools per denomination')
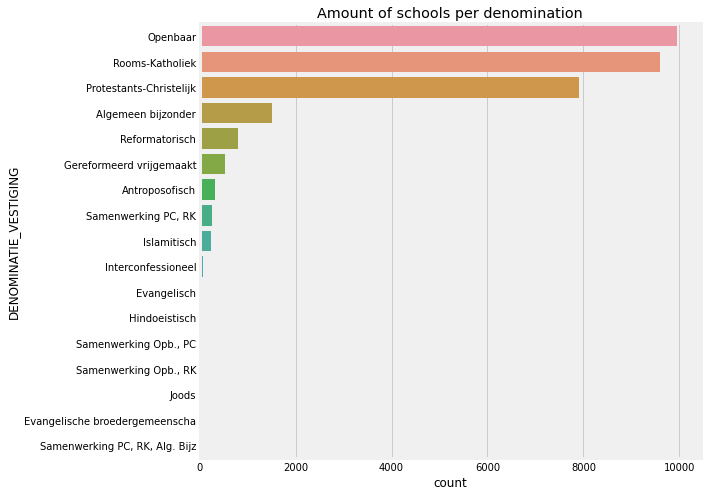
The last plot above shows us that there are several values of the DENOMINATIE_VESTIGING column with a relatively small amounts of observation. Probably these values won’t be statistically significant in the entire dataset.
plt.figure(figsize=(5, 5))
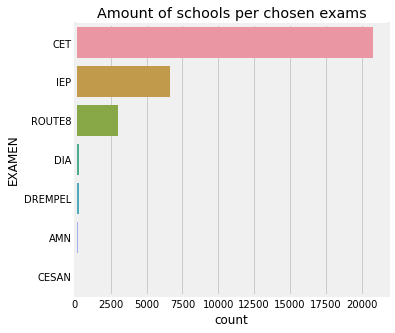
ax = sns.countplot(y='EXAMEN',data=categorical_data, order = data['EXAMEN'].value_counts().index)
ax.set_title('Amount of schools per chosen exams')
Text(0.5, 1.0, 'Amount of schools per chosen exams')
Bivariate analysis
In this part I’m going to see is there any relashionship between variables.
Relationship between continuous variables
To analyse relashionships between continuous variables I will build a correlation matrix and then take a look at the scatterplots of the most correlated variables:
corr_matrix = numeric_data.corr()
f, ax = plt.subplots(figsize = (14,12))
plt.title('Correlation of numeric factors', y = 1, size = 16)
sns.heatmap(corr_matrix, vmax = .8, annot_kws={'size': 8}, annot = True, square=True)
<AxesSubplot:title={'center':'Correlation of numeric factors'}>
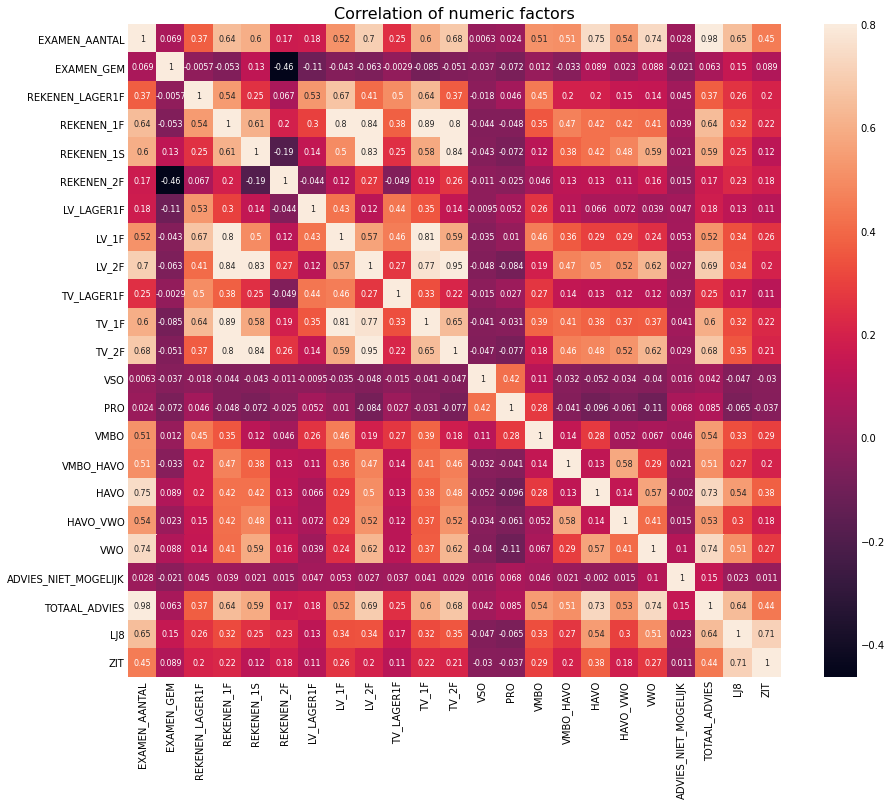
The correlation matrix shows us that there are not a lot of variables correlated with each other. Most of the variables which have a correlation between each other are about number of students who know math or language on different levels and numbers of school advices for high education (HAVO_VWO and VWO). Let’s take a look at the paired scatterplots of the most correlated variables
numeric_data.columns
Index(['EXAMEN_AANTAL', 'EXAMEN_GEM', 'REKENEN_LAGER1F', 'REKENEN_1F',
'REKENEN_1S', 'REKENEN_2F', 'LV_LAGER1F', 'LV_1F', 'LV_2F',
'TV_LAGER1F', 'TV_1F', 'TV_2F', 'VSO', 'PRO', 'VMBO', 'VMBO_HAVO',
'HAVO', 'HAVO_VWO', 'VWO', 'ADVIES_NIET_MOGELIJK', 'TOTAAL_ADVIES',
'LJ8', 'ZIT'],
dtype='object')
columns = ['REKENEN_LAGER1F', 'REKENEN_1F', 'REKENEN_1S', 'REKENEN_2F', 'LV_LAGER1F', 'LV_1F', 'LV_2F',
'TV_LAGER1F', 'TV_1F', 'TV_2F', 'HAVO_VWO', 'VWO']
corr_data = numeric_data[columns]
corr_data.head()
| REKENEN_LAGER1F | REKENEN_1F | REKENEN_1S | REKENEN_2F | LV_LAGER1F | LV_1F | LV_2F | TV_LAGER1F | TV_1F | TV_2F | HAVO_VWO | VWO | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 4 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 |
sns.pairplot(corr_data)
<seaborn.axisgrid.PairGrid at 0x12125c7c0>
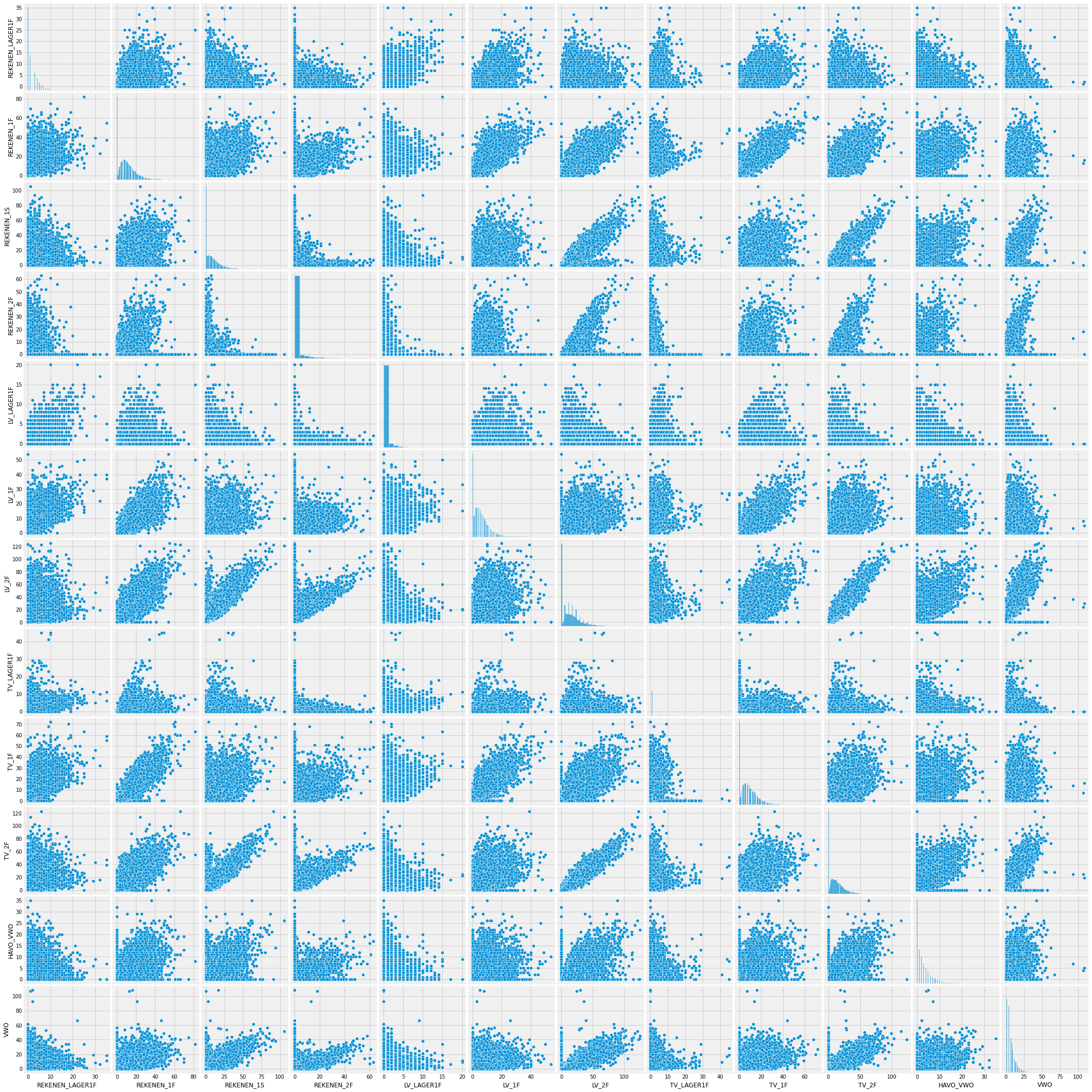
I would assume that if in a particular school students don’t know math well, they should know languages better. But looking at the plots above I see some correlation between numbers of students who don’t have good knowledge in either subject. It’s probably not enough to deny my assumption, though it just shows the level of education that students receive in the school.
Relationship between categorical variables
We can find the relashionship between categorical variables using 2 ways:
- Encode categorical variables to numeric ones and then use a correlation matrix
- Calculate Cramer’s V statistic.
Let’s use the first one to see if there is any relationship between categorical variables:
from sklearn.preprocessing import LabelEncoder
for column in categorical_data.columns:
categorical_data[column] = LabelEncoder().fit_transform(categorical_data[column])
print(categorical_data.columns)
categorical_data.head()
Index(['DATUM', 'INSTELLINGSNAAM_VESTIGING', 'POSTCODE_VESTIGING',
'PLAATSNAAM', 'GEMEENTENAAM', 'PROVINCIE', 'SOORT_PO',
'DENOMINATIE_VESTIGING', 'EXAMEN'],
dtype='object')
| DATUM | INSTELLINGSNAAM_VESTIGING | POSTCODE_VESTIGING | PLAATSNAAM | GEMEENTENAAM | PROVINCIE | SOORT_PO | DENOMINATIE_VESTIGING | EXAMEN | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 2553 | 1401 | 1809 | 403 | 11 | 0 | 4 | 2 |
| 1 | 0 | 147 | 4026 | 1134 | 210 | 5 | 0 | 12 | 2 |
| 2 | 0 | 2335 | 1565 | 196 | 227 | 11 | 0 | 9 | 2 |
| 3 | 0 | 3993 | 4354 | 670 | 271 | 3 | 0 | 9 | 2 |
| 4 | 0 | 4496 | 6459 | 1081 | 253 | 4 | 0 | 9 | 2 |
corr_categorical_matrix = categorical_data.corr()
f, ax = plt.subplots(figsize = (14,12))
plt.title('Correlation of numeric factors', y = 1, size = 16)
sns.heatmap(corr_categorical_matrix, vmax = .8, annot_kws={'size': 8}, annot = True, square=True)
<AxesSubplot:title={'center':'Correlation of numeric factors'}>
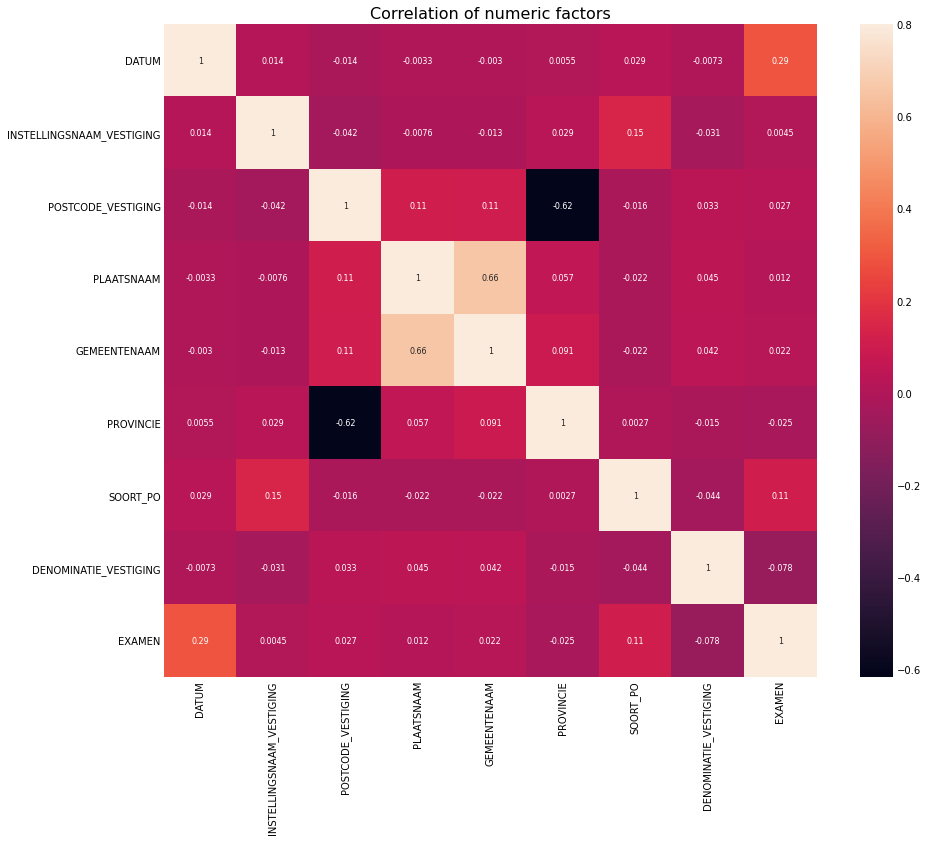
We can see almost no correlation between variables. Only between PLAATSNAAM and GEMEENTENAAM there is some, and also between POSTCODE_VESTIGING and PROVINCIE. However it was expected because these variables represent actually the same info in different forms - a place where the school is located.
Plots
To get some insights from the data let’s add some new variables:
data["GOOD_MATH"] = data['REKENEN_1F'] + data['REKENEN_1S'] + data['REKENEN_2F']
data["GOOD_LANGUAGE"] = data['LV_1F'] + data['LV_2F'] + data['TV_1F'] + data['TV_2F']
data["HIGH_EDUCATION"] = data['HAVO'] + data['HAVO_VWO'] + data['VWO']
data["ZIT_PER"] = data['ZIT']/data['LJ8']
data.head()
| SCHOOL_ID | DATUM | INSTELLINGSNAAM_VESTIGING | POSTCODE_VESTIGING | PLAATSNAAM | GEMEENTENAAM | PROVINCIE | SOORT_PO | DENOMINATIE_VESTIGING | EXAMEN | ... | HAVO_VWO | VWO | ADVIES_NIET_MOGELIJK | TOTAAL_ADVIES | LJ8 | ZIT | GOOD_MATH | GOOD_LANGUAGE | HIGH_EDUCATION | ZIT_PER | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 000AP_2015 | 2015 | De Schanskorf | 2715BT | ZOETERMEER | Zoetermeer | Zuid-Holland | Bo | Gereformeerd vrijgemaakt | CET | ... | 1 | 1 | 0 | 11 | 13 | 0 | 0 | 0 | 7 | 0.000000 |
| 1 | 000AR_2015 | 2015 | BS "De Maasparel" | 6109AM | OHE EN LAAK | Maasgouw | Limburg | Bo | Rooms-Katholiek | CET | ... | 0 | 6 | 0 | 18 | 17 | 0 | 0 | 0 | 13 | 0.000000 |
| 2 | 000AZ_2015 | 2015 | De Kiezel en de Kei | 2971AR | BLESKENSGRAAF CA | Molenwaard | Zuid-Holland | Bo | Openbaar | CET | ... | 2 | 4 | 0 | 22 | 19 | 3 | 0 | 0 | 9 | 0.157895 |
| 3 | 000BA_2015 | 2015 | OBS De Klimboom | 6666EB | HETEREN | Overbetuwe | Gelderland | Bo | Openbaar | CET | ... | 4 | 0 | 0 | 12 | 24 | 5 | 0 | 0 | 5 | 0.208333 |
| 4 | 000BB_2015 | 2015 | Obs Letterwies | 9944AR | NIEUWOLDA | Oldambt | Groningen | Bo | Openbaar | CET | ... | 0 | 2 | 0 | 16 | 15 | 2 | 0 | 0 | 7 | 0.133333 |
5 rows × 37 columns
Let’s see some plots for these new variables:
columns = ['GOOD_MATH', 'GOOD_LANGUAGE', 'HIGH_EDUCATION', 'ZIT_PER', 'PROVINCIE']
new_data = data[columns]
sns.pairplot(new_data, hue = 'PROVINCIE')
<seaborn.axisgrid.PairGrid at 0x11f298850>
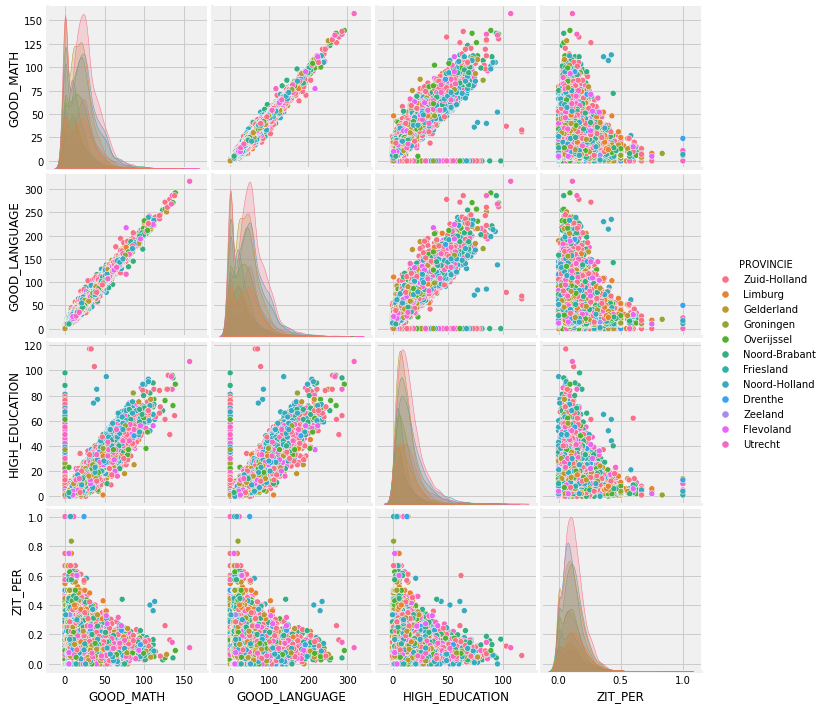
Plots above show us that there is probably a negative relashionship between the amount of students who stay in a primary school longer and a quality of knowledge. We can also see a strong positive correlation between a good knowledge of math&language and school’s recommendation for a higher education. As we see this strong positive correlation, we don’t really need to explore all 3 columns (‘GOOD_MATH’, ‘GOOD_LANGUAGE’ and ‘HIGH_EDUCATION’), instead we can look at the plots for only one of them in relation to other interesting variables:
categorical_features = ['PROVINCIE', 'DENOMINATIE_VESTIGING', 'EXAMEN', 'DATUM']
for column in categorical_features:
data[column] = data[column].astype('category')
if data[column].isnull().any():
data[column] = data[column].cat.add_categories(['MISSING'])
data[column] = data[column].fillna('MISSING')
def boxplot(x, y, **kwargs):
sns.boxplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(data, id_vars=['HIGH_EDUCATION'], value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(boxplot, "value", "HIGH_EDUCATION")
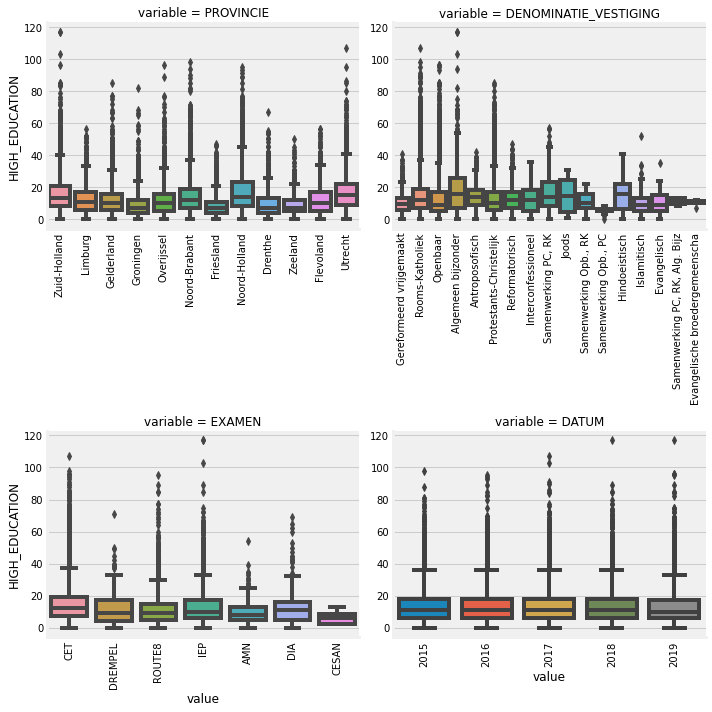
f = pd.melt(data, id_vars=['ZIT_PER'], value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(boxplot, "value", "ZIT_PER")
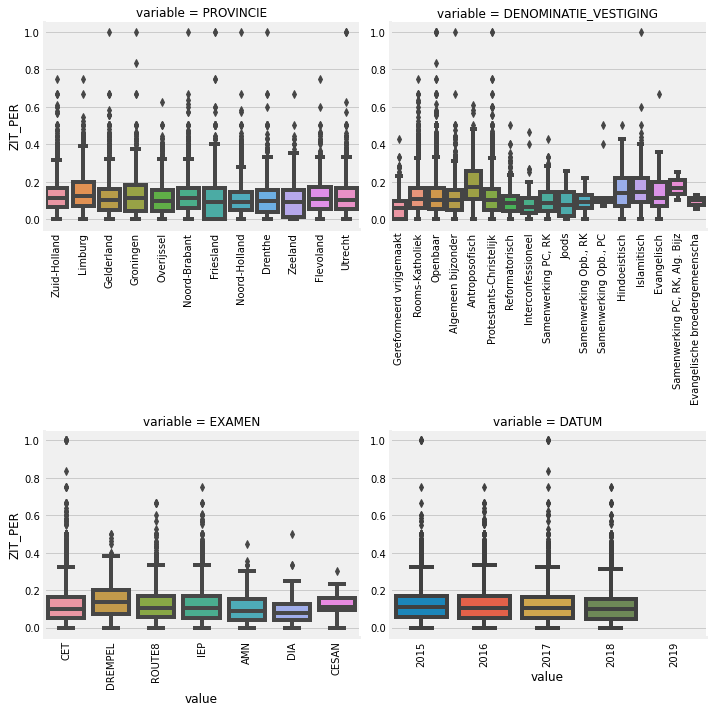
And finally let’s take a look at some plots for the CET exam:
data_CET = data[data['EXAMEN'] == "CET"]
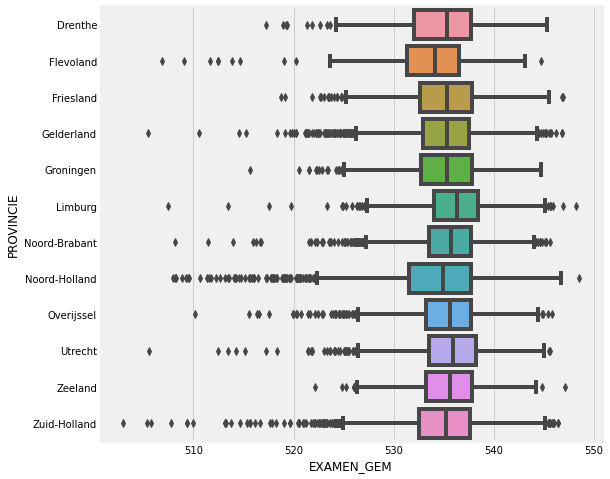
f, ax = plt.subplots(figsize=(8, 8))
fig = sns.boxplot(x='EXAMEN_GEM', y="PROVINCIE", data=data_CET)
f, ax = plt.subplots(figsize=(8, 8))
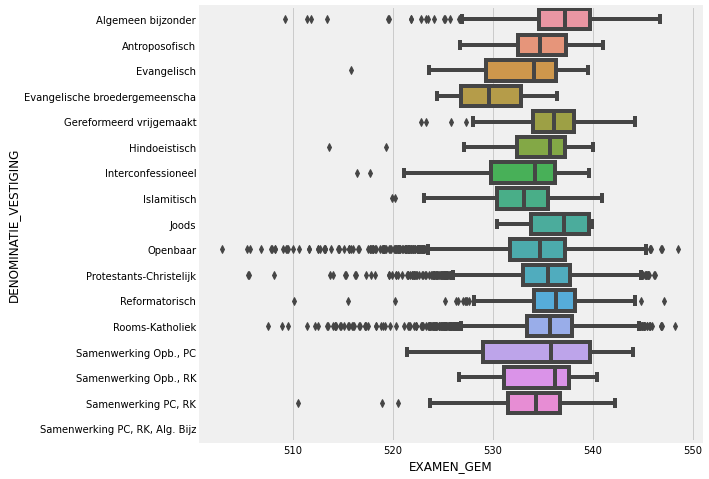
fig = sns.boxplot(x='EXAMEN_GEM', y="DENOMINATIE_VESTIGING", data=data_CET)
sns.relplot("HIGH_EDUCATION", "EXAMEN_GEM", data=data_CET)
<seaborn.axisgrid.FacetGrid at 0x108882550>
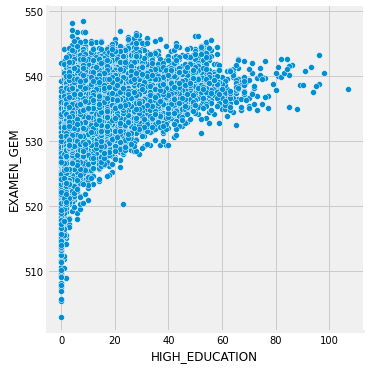
We can see on the plot above that the higher the CET score is, the bigger amount of students gets an advice for a high education.
Conclusion
As a result of this data analysis I can say that we now have data about schools in The Netherlands for years 2015-2018. It contains mostly info about schools locations, scores on the final exams, numbers of students on different levels of knowledge and data about schools advices for a secondary education. After looking at the dataset and plots built out of this data, I can conclude that students who have good knowledge in math and language have bigger chances to get a school advice for a high education. Also we can say from the analysis that a quality of education in a school could be estimated by its average score on the final exam or a number of students who know well both math and language.